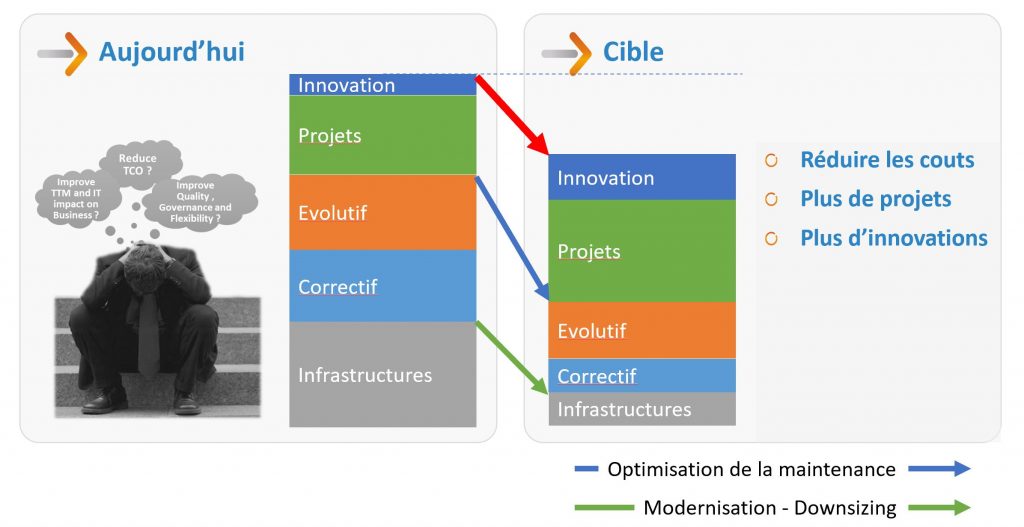
Les enjeux des DSI et des directions générales peuvent être résumés par la nécessité d’Acquérir ou conserver un avantage concurrentiel grâce à son SI.
En d’autres termes, avoir un système plus efficace en termes de productivité à moindre coût.

Les enjeux des DSI et des directions générales peuvent être résumés par la nécessité d’Acquérir ou conserver un avantage concurrentiel grâce à son SI.
En d’autres termes, avoir un système plus efficace en termes de productivité à moindre coût.
Cela se décline en chantier de
Il faut avoir en tête que la plupart de ces problématiques sont liées car le premier frein à la réduction des coûts et à la mise en place de processus agiles est lié aux adhérences des technologies utilisées avec des infrastructures obsolètes, chères à exploiter et/ou ne permettant pas de profiter des nouveaux outils et méthodes de développement.
Rationaliser son système et ses méthodes nécessite une modernisation technologique mais sans casser la dynamique commerciale du métier car « la vente continue pendant les travaux ».
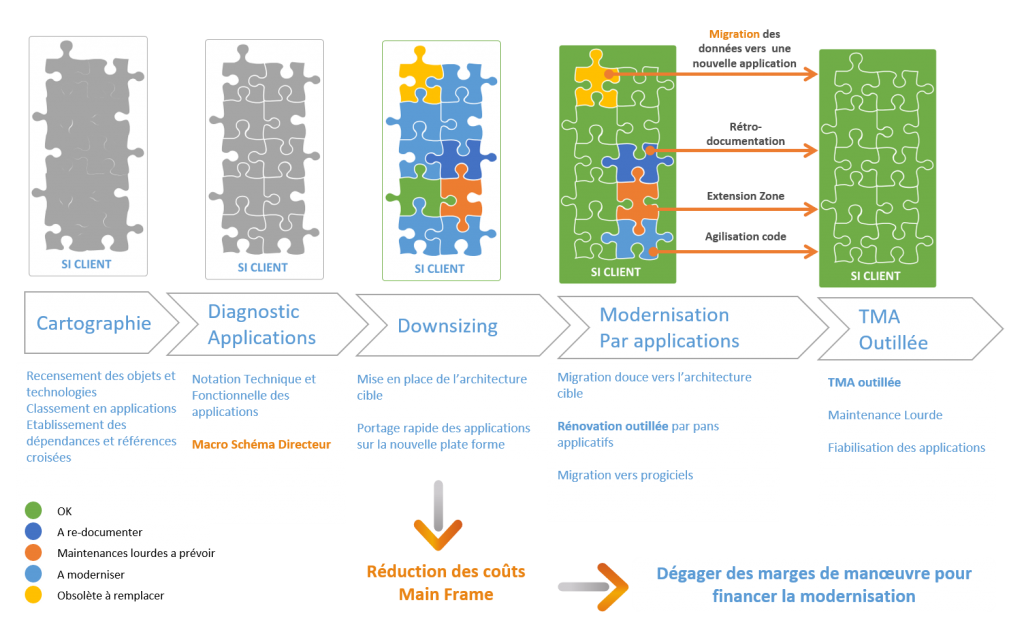
La première étape de la rationalisation consiste à faire un état des lieux qui passe par un recensement technique et fonctionnel de son patrimoine.
Reprendre le contrôle de ses applications passe par la connaissance de ce qui est réellement exécuté en production. Cela n’est pas toujours le cas notamment sur des environnements Mainframe.
Voici quelques questions qui permettent de comprendre la problématique sur Mainframe :
Si vous avez répondu oui à une de ces questions ou si vous ne savez pas y répondre, il est probable qu’il y ait des axes d’amélioration sur vos processus de gestion de configuration et de maintenance.
L’objectif d’une gestion de configuration est de permettre de reconstruire en totalité une production à partir des sources des applications. Très peu d’organisations sont en mesure de le faire sur Mainframe.
Sur les applications développées dans des langages modernes comme Java, il existe un grand nombre d’outils et d’usages permettant de bien gérer son patrimoine. Cependant, par manque de temps ou de moyens, on fait souvent du court terme.
Par exemple, pour disposer d’un référentiel de non régression à jour permettant de faire de l’intégration continue, il faudrait mettre en place une procédure de correction d’anomalie consistant à commencer par reproduire l’anomalie avec un cas de test qui viendra enrichir le référentiel avant de corriger l’anomalie. Là encore, peu le font réellement.
Les patrimoines Client / Serveur sont entre les deux avec le plus souvent des applications gérées dans des gestionnaires de configuration mais des usages de programmation s’appuyant sur des langages évènementiels et souvent permissifs ce qui implique une explosion du nombre de cas de déclenchement d’un traitement. La programmation évènementielle n’ayant été que tardivement normée, on observe une duplication des traitements alors qu’il aurait fallu fonctionnaliser au maximum pour optimiser et sécuriser les évolutions et la maintenance.
L’accès aux données est également souvent géré de manière dispersée avec des requêtes saupoudrées dans tout le code, rendant délicate toute modification du modèle de données.
Quand la partie Cliente développée dans un L4G Client / Serveur s’appuie sur une partie Serveur sur Mainframe, il est très difficile d’avoir une vision de bout en bout de la transaction qui passe techniquement par différente couches applicatives et middleware et est de plus administrée par plusieurs équipes de développement.
Il est compliqué de tenir le cap optimum. Il convient d’être rationnel et de ne pas subir le régime des ayatollahs de la norme.
Avec une équipe expérimentée et connaissant très bien les applications, on peut faire quelques impasses et l’intuition des développeurs compensera le manque de rigueur. Mais tout à un prix, tôt ou tard, on subira un départ à la retraite, une démission, l’inflation mécanique des salaires et les résistances au changement.
Une bonne ligne nous semble être de profiter des apports technologiques en mettant en place la technologie et les processus permettant d’avoir une vue exhaustive de son patrimoine et des interdépendances entre les composants de manière à :
La cartographie technique consiste à collecter tous les sources de tous les composants (Programmes, sous-programmes, JCL, Données, Copy, etc…) et de tirer entre eux les références croisées de manière identifier pour chaque composant :
Sur la base des points d’entrée TP et Batch, l’atelier délimite le périmètre utile des composants et produits 2 listes
Il est nécessaire de collecter les sources des Missings qui potentiellement peuvent tirer des références vers de nombreux objets Unrefs.
Compléter la liste des points d’entrée permet également de référencer des composants identifiés comme Unrefs.
On voit bien qu’il s’agit d’un processus itératif et que le nombre d’itération dépendra de la qualité de la gestion de configuration.
On pourra compléter la cartographie Technique par une cartographie Fonctionnelle qui consiste à recenser la liste des fonctions ou applications métier. La granularité de ce recensement est un élément important pour permettre l’exploitation de ces informations.
On décrira la fonctionnellement la fonction ou l’application et on isolera le ou les points d’entrée.
Le point d’entrée associé à chaque fonction ou application permet de lister de manière exhaustive les composants qui la supporte par application des références croisées issues de la cartographie Technique.
Les références croisées étant cross-technologie, on pourra suivre une transaction de bout en bout depuis le Front Client / Serveur ou Web jusqu’à la Table de la base de données DB2 sur Mainframe en passant par la transaction CICS développée en COBOL.
Diagramme de la cartographie Technique et Fonctionnelle:

On pourra « scorer » la fonction ou l’application d’un point de vue tant technique, fonctionnel ou financier de manière à objectiver un macro schéma directeur qui permettra application par application de définir une cible optimum.
Diagramme de la démarche de rationalisation:
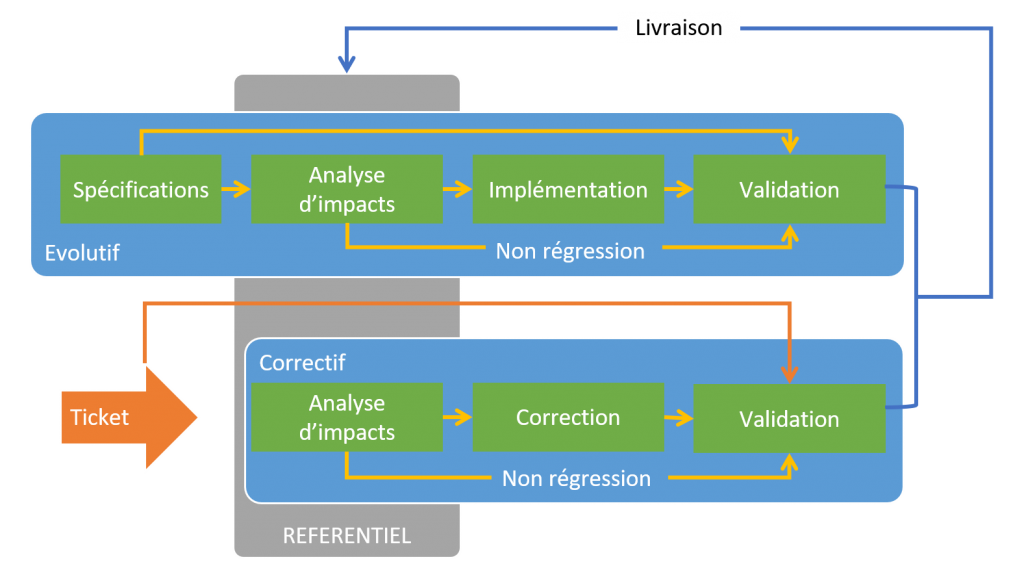
La mise en œuvre d’un tel référentiel, permet de faciliter les opérations de maintenance Correctives et Evolutives sur l’ensemble du patrimoine.
Pour le Correctif, on identifiera plus facilement l’origine du dysfonctionnement en isolant la liste des instructions qui manipulent la structure de donnée dans laquelle on a localisé une anomalie et on pourra naviguer dans les sources de programmes en suivant les appels.
On pourra mesurer avant mise en place, l’impact de la correction envisagée sur les composants qui utilise la ressource que l’on modifie, afin de limiter les effets de bord.
Pour l’Evolutif, le périmètre technique de la fonction que l’on souhaite faire évoluer est directement disponible. On identifiera plus facilement le meilleur endroit pour implémenter l’évolution.
Les impacts des modifications sur les autres composants sont directement disponibles et permettent d’anticiper les effets de bord et facilitent la prise en compte des modifications nécessaires.
Ces analyses pouvant être menées en amont, l’estimation des charges sera plus fiable et la mise en œuvre plus économique.
Diagramme des étapes de la Maintenance Applicative:
Disposer d’un tel référentiel permet en outre d’automatiser un certain nombre d’opérations répétitives qu’un développeur réalise tout au long du projet.
Par exemple, on pourra générer des JCL ou scripts de rafraichissement de données sur la base des données modifiées par un programme ou un ensemble de programmes (Tous les programmes exécutés par un même JCL par exemple).
On estime qu’un développeur passe 15 à 20% de son temps à rafraichir les données de test. Les gains peuvent être conséquents.