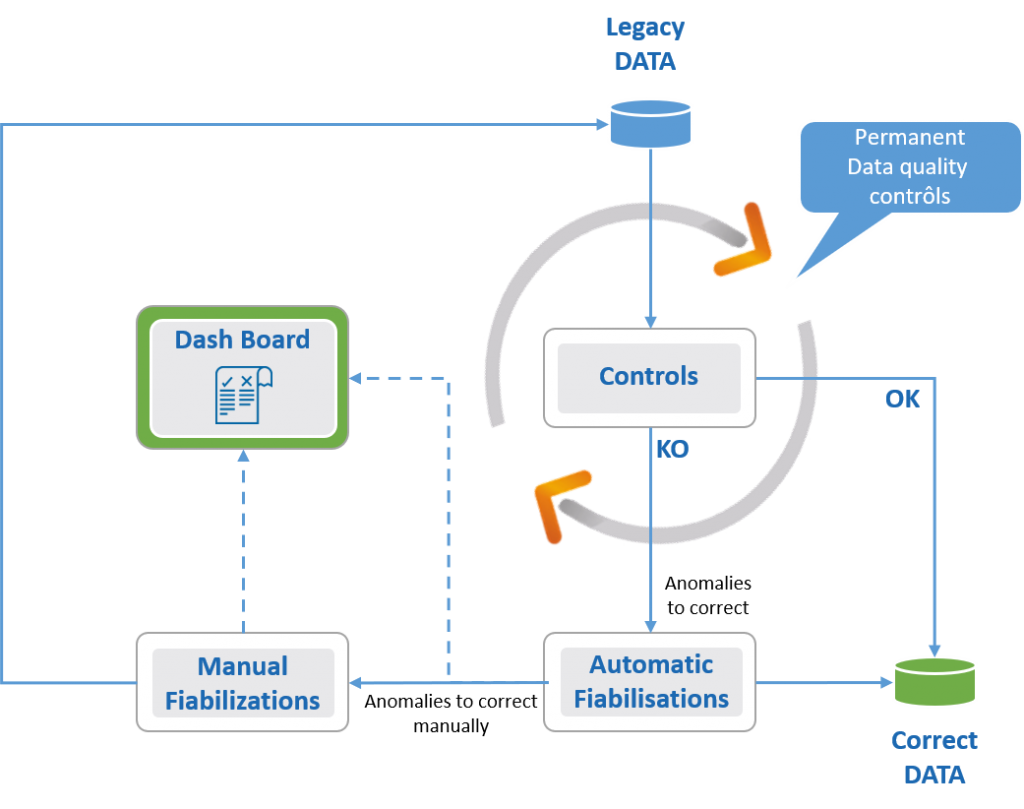
Data cleansing helps you control and improve the quality of your data by comparing it to the integrity and management rules of its system or of the system you wish to migrate to.
Data quality is often overestimated and can be altered for many ―sometimes very good― reasons:
- Obsolescence of the system:
- Lack of control over certain standardized structures, for instance postal addresses that are not in accordance with post office regulations and require to be standardized
- No referential integrity of the data model
- Lack of application controls
- Duplicates created unintentionally or deliberately: Duplicates are quite common for natural persons or legal entities. It is often unintentional / users often create them unintentionally but it can be deliberate because it is a way to make up for the failings of an application
- Misuse of certain structures by users to manage new information
- Data discrepancy due to application bugs corrected late
- Information missing, forcing information, bypassing controls, etc.
Poor data quality eventually leads to significant costs.
Direct costs:
- High postal fares due to poor address quality, or multiple duplicate mailing
- Application crash
- Approximate or even false statistics
- Impossibility of consolidating information which is sometimes regulatory
- Data reliability is necessary when creating a new application or system
- Etc.
Indirect costs:
- Loss of image
- Loss of productivity
- Etc.