Data migration or data recovery projects are encountered in different situations such as:
- Establishment of a software package or a new development
-
Information Systems Convergence in order to rationalize IT and reduce costs
Your data migration project involves transporting your data from your old environment to your new system, which has a completely different data model as well as management rules.
Within a limited timeframe and budget, you need to populate new data structures according to their own integrity rules. The objective is not so much to migrate the Source data as to ensure that the Target System works correctly with the migrated data. Quite a different story!
Migrating your data to your new system or software package without disrupting your business is a project in itself whose complexity is often underestimated:
-
The source system is often only mastered by a small number of people, who are, for the most part, already critical resources on the project to implement the target solution,
-
- Due to their design, the new systems are less permissive and require a high quality of data as well as information that may not have been managed – or badly – in the source: a costly data enrichment and reliability project, requiring a high level of project management is therefore necessary.
- The switchover must be able to occur during a WE whatever the volume of data. The performance of the migration chain is therefore critical.
Data migration is often illustrated by using reference data such as name, surname, address as a reference. Taking such examples leads to greatly underestimating the complexity of the migration, which on such data comes down to simple « MOVE ».
Complex migration issues are found in calculated data and date sequences.
Migrating a portfolio of Bank Credits will require, for example, to adjust the settings so that future maturities are calculated in the same way on the Source and the Target, whereas the calculation engines are different and can generate discrepancies which will inevitably give rise to questions or complaints from customers.
The necessary adjustments to the migration rules can only be managed by an iterative process.
It is therefore crucial to be able to iterate quickly and well. That is to say quickly implementing changes to migration rules without regression. This is the key to the success of a migration project.
Data migration is not like any other development project and cannot be carried out efficiently with standard development means.
In a general way :
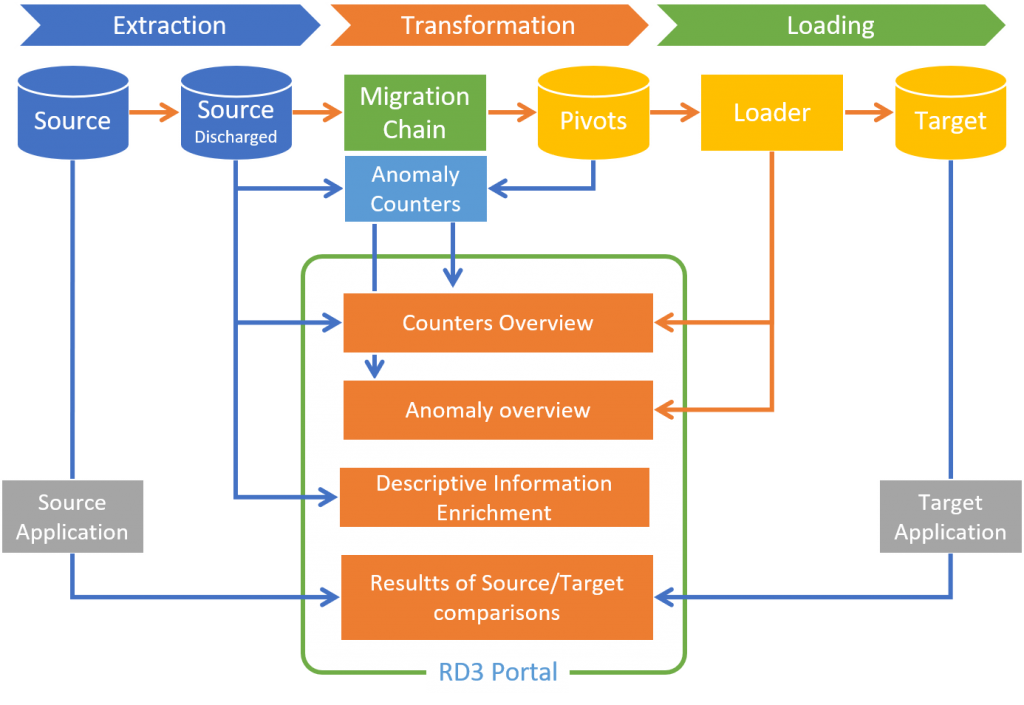
. Even if the editors tell you the opposite, ETLs or SQL are not suitable for large volumes and a rapid iteration cycle. These technologies also do not make it possible to produce technical and functional counters making it possible to verify that Lavoisier’s law also applies to data migration: « Nothing is lost, nothing is created, everything is transformed »
. We have been asked many times to get out of the rut of projects carried out with reputable ETLs which required extravagant machine resources for poor performance.
. Conventional development languages are not productive enough and do not allow us to have control over the specifications. In practice, after a few iterations, the rules are no longer defined except in the code and in the developer’s mind, who then becomes a bottleneck and a risk to the project.
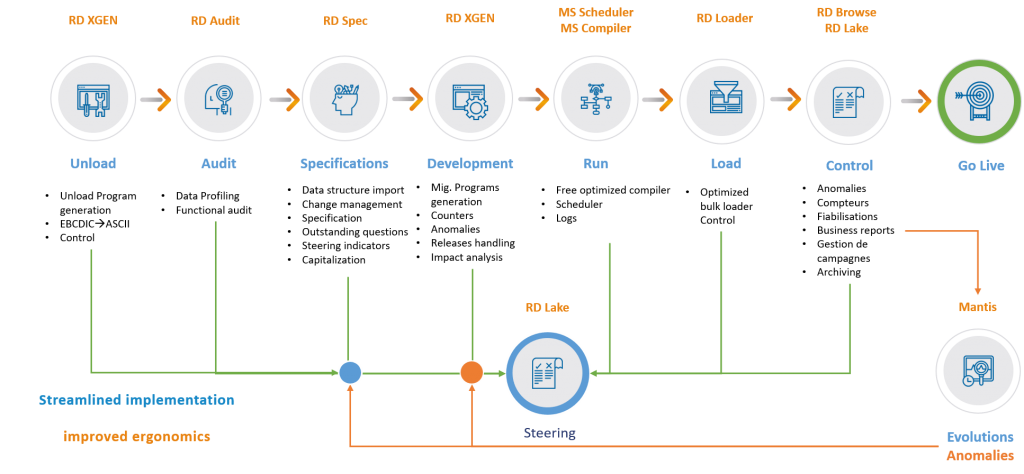
For all these reasons, we have developed over the years a dedicated technology based on the generation of code from specifications.